
Tabellen.
Statistische analyses hebben des te meer zin, als er meer data zijn. Daarom maken we gebruik van een al ingevuld data bestand voor de onderdelen grafieken en tabellen. Download het bestand observatie_presenteren_data.sav. Dit doe je door rechts te klikken op de naam van het bestand en vervolgens uit het menu kiezen voor opslaan als. Sla het bestand op een voor jou toegankelijke plek op.
Open het bestand door in Windows Verkenner twee keer op de bestandsnaam te klikken of kies in SPSS uit het menu File --> open --> data.
In SPSS moet je het volgende zien krijgen:
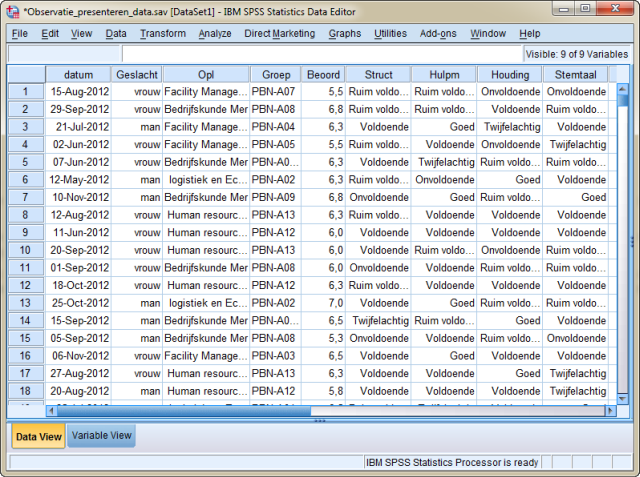
Wanneer je welke tabel gaat gebruiken kun je halen uit de eerste twee kolommen van onderstaand schema onder het kopje numeriek.
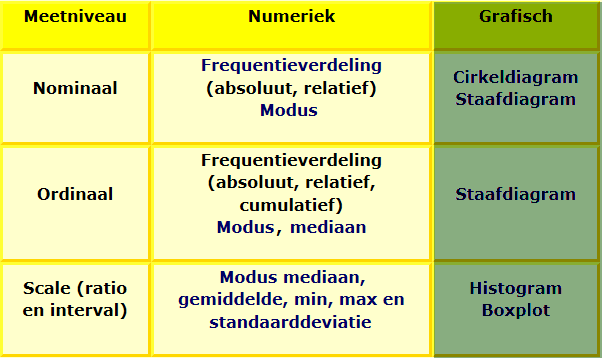
Bepaal eerst het meetniveau van de variabele, en vervolgens kijk je onder Numeriek welke mogelijkheden er zijn.
Het meetniveau kun je zien in de variabele view. Schakel naar dit scherm over en je ziet:
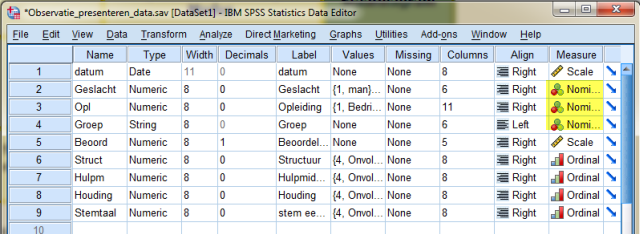
Dus voor de variabelen Geslacht, Opl en groep kunnen we een frequentietabel maken met absolute en relatieve waarden. Dit doen we als volgt:
Kies in het menu van SPSS voor de optie “Analyze”.
Kies dan voor Descriptive Statistics en vervolgens voor Frequencies.
Je komt dan in het volgende scherm.
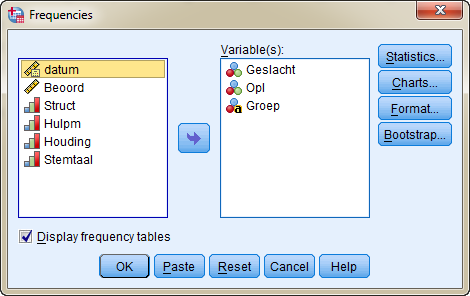
Verplaats de nominale variabelen geslacht, opl en groep in het rechter hokje door op de naam van de variabele te klikken en vervolgens op de pijl tussen de twee hokjes te klikken.
Klik daarna op OK. Je komt dan in het outputscherm waarin vier tabellen staan. De eerste tabel geeft aan dat hoeveel valide metingen er gedaan zijn. Bij geslacht zie je dat er van de 400 metingen ook 400 ingevuld zijn. Bij opleiding zie je dat er bij een persoon geen opleiding staat. Zoek je deze persoon op dan blijkt dit persoon 184 te zijn (ga na). Bij die persoon zie je dat de klas wel ingevuld is, namelijk PBN-A13. Het betreft dus een Logistiek en Economie student.
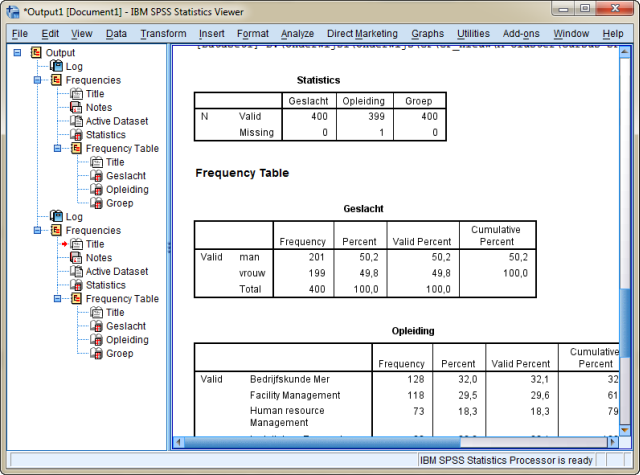
In de tabel waarin de aantallen en percentage van de opleiding aangegeven worden komt de missing value ook terug. In deze tabel zie je ook dat er een verschil is tussen de kolom “Percent” en de kolom “Valid Percent”. Het verschil zit hem in het volgende: De kolom Percent geeft aan van alle respondenten het percentage dat voorkomt, de kolom “Valid Percent” alleen van die personen waar iets ingevuld is. De kolom “Valid Percent” is vooral van belang als er van die vraag heel veel non-respons is (dus missing values).
Bij nominale variabelen heeft het geen zin om het cumulatieve percentage weer te geven. Ook als de kolom “Percent” en “Valid Percent” gelijk zijn, kun je deze kolommen beter verwijderen.
Het verwijderen van een kolom gaat als volgt:
Klik tweemaal in de tabel. Doe je dit in de tabel geslacht dan zal in eerste instantie de kop van de tabel (dus waar geslacht in staat) zwart kleuren.
Selecteer vervolgens met de muis de waarden in de tabel zoals in onderstaande schermafdruk.

Druk dan op de “Delete” knop op je toetsenbord en het resultaat moet er als volgt uitzien.
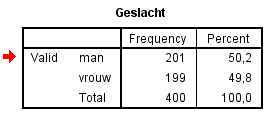
Wil je de tabel verder verfraaien door bijvoorbeeld Valid weg te halen, dan gaat dat op vergelijkbare wijze. Ook kun je teksten aanpassen door er op te klikken. Probeer volgende tabel maar eens te maken.
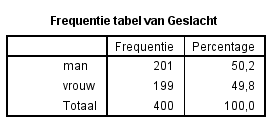
De waarde die het meeste voorkomt is de Modus. Bij de variabele geslacht is dit Man. Bij opleiding is dit bedrijfskunde Mer en bij PBN-A10.
Let op Die aantallen geven niet aan hoeveel studenten er in die klas zitten, maar geven het aantal presentaties die gemeten zijn weer.
Bekijken we weer het Variabele View scherm dan zien we:
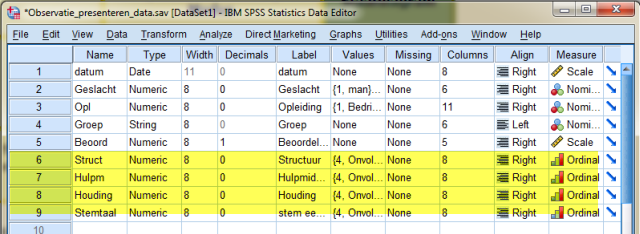
Dat de variabelen struct, hulpm, houding en stemtaal ordinaal zijn (dit in tegenstelling tot het voorbeeld zoals eerder zelf gemaakt).
Dat de waarden onvoldoende, twijfelachtig , voldoende, ruim voldoende en goed zijn (ga na).
Vaak wordt dit gedaan bij een beperkt aantal waarden (hier zijn het er maar vijf). Doordat ik maar een beperkt aantal heb kan ik toch een frequentie tabel maken (bij de variabel Beoord kan dit niet omdat het aantal verschillende cijfers bijna onbeperkt is. Je zou dus een heel lange tabel krijgen, waarbij iedere waarde misschien een of twee keer voorkomt.
De variabelen zijn wel ordinaal omdat de waarden te ordenen zijn. Vier is de kleinste, Acht de grootste.
In het schema kunnen we zien dat bij een ordinale variabele het volgende kunnen doen.

Kies weer voor Analyze --> Descriptives statistic --> frequencies, klik op “Reset” en verplaats onderstaande variabelen naar rechts.
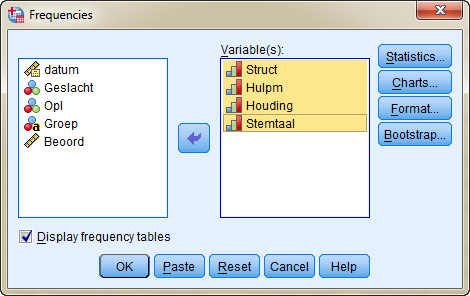
Klik daarna op OK.
Je krijgt onderstaande output.
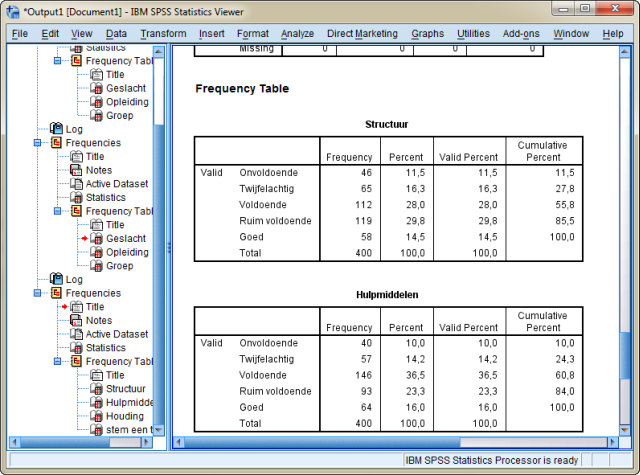
Wil je de modus en de mediaan ook berekenen, zorg dan dat je weer in het Frequencies instelscherm (zie hieronder) komt en klik op de knop statistics.
In het scherm dat je dan krijgt klik je de modus, de mediaan en eventueel de kwartielen aan.
Klik op Continue en OK.
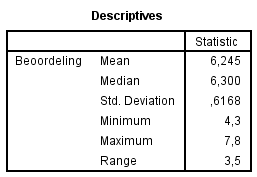
Blijft nog over de scale variabele Beoord. Voor een scale variabele hebben we de volgende mogelijkheden:

Al deze mogelijkheden kunnen we vinden onder Analyze --> Descriptives statistic --> Explore. Je komt dan in het explore scherm.
Verplaats de variabele Beoord onder “Dependent List”.
Klik bij Display Statistics aan en klik op OK en je krijgt het volgende scherm te zien:
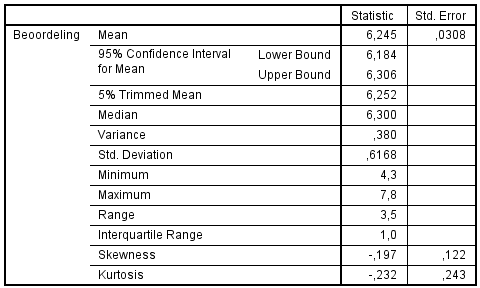
Ik kan me voorstellen dat er nu teveel informatie in de tabel staat (in ieder geval informatie die je nu nog niet begrijpt). Je kunt de tabel dan aanpassen, door er tweemaal op te klikken en delen weg te halen.
Doe dit zodat uiteindelijk onderstaande tabel verschijnt.
Kruistabellen.
Wil je verbanden of samenhang of verschillen tussen verschillende variabelen aantonen dan kun je gebruik maken van Kruistabellen. Wil je bijvoorbeeld weten per opleiding of er een verschil in aantallen presentaties gedaan door vrouwen is, dan maak je een kruistabel.
Een kruistabel maak je door te kiezen voor Analyze --> Descriptives statistic --> Crosstabs.
Vul het crosstab scherm als volgt in:
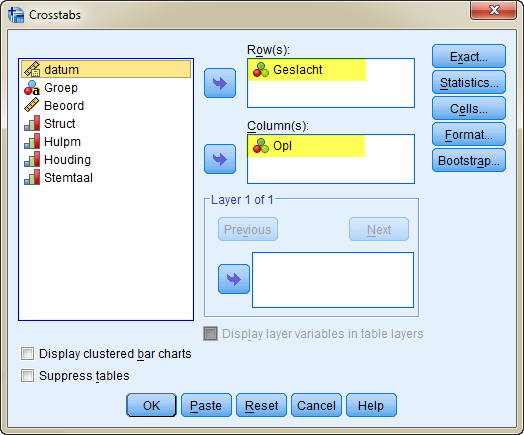
En klik op OK. De output zal zijn:
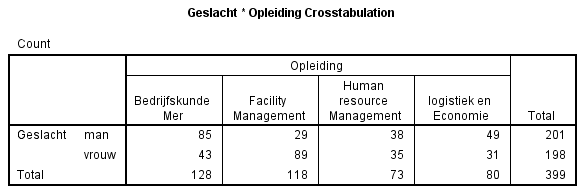
Hierin staan aantallen. Bij aantallen moeten wij twee keer kijken wat er aan te hand is. Vaak is het ook verwarrend omdat bij de ene variabele veel meer metingen zijn dan bij de andere. We werken dan liever met percentages. Wat we graag zouden zijn is dat van Bedrijfskunde MER zoveel procent man en zoveel procent vrouw is, en dat ook van de andere variabelen. Dit kan door opties in het Crosstab scherm in te stellen. Ga daarvoor naar het crosstab scherm en klik op cells.
Je krijgt het volgende scherm. Vul dit als volgt in:
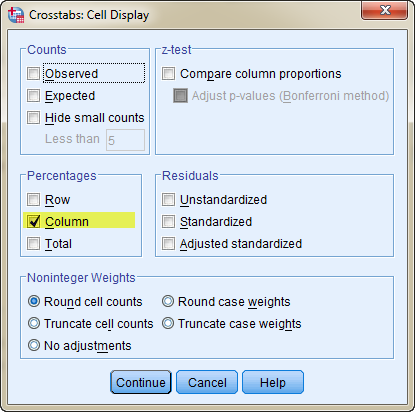
Per kolom worden nu de percentages berekend. Het resultaat is als volgt:
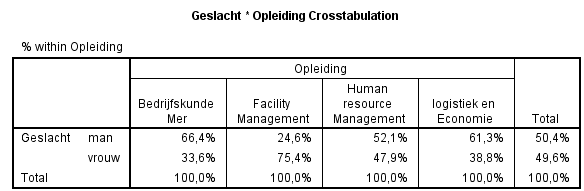
Wat nu direct opvalt is dat bij Bedrijfskunde MER veel meer mannen gepresenteerd hebben, bij facility management veel meer vrouwen en bij HRM en logistiek zijn de mannelijke presentaties ook in de meerderheid.
Met Crosstabs kan ik maar beperkt kruistabellen maken. In het B-cluster leer je hoe je zeer uitgebreide kruistabellen kunt maken met het Analyze --> tables --> Custom Tables commando.